Machine Learning, a rapidly evolving field, empowers computers to learn from data without explicit programming. It’s a fascinating blend of statistics, algorithms, and computer science that enables systems to identify patterns, make predictions, and improve performance over time. From healthcare diagnostics to personalized recommendations, machine learning is transforming various sectors. This guide will delve into the core concepts, algorithms, and practical applications of machine learning, while also addressing ethical considerations and future trends.
This guide will walk you through the foundational concepts of machine learning, covering different types of learning, algorithms, and data preprocessing techniques. We will also explore real-world applications, the importance of model evaluation, and ethical considerations for responsible development and deployment. Furthermore, the guide will equip you with knowledge about the tools and libraries used in machine learning, highlighting the key differences and use cases of various algorithms.
The future trends in machine learning will also be examined, along with practical steps in deploying and maintaining models in a production environment.
Introduction to Machine Learning
Machine learning is a rapidly evolving field of artificial intelligence that empowers computers to learn from data without explicit programming. Instead of relying on pre-defined rules, machine learning algorithms identify patterns, make predictions, and improve their performance over time as they are exposed to more data. This iterative process of learning from data is a cornerstone of many modern applications.Core to machine learning is the concept of utilizing algorithms to extract insights and make decisions based on the data they are trained on.
Machine learning is rapidly evolving, and its applications are expanding. This is particularly evident in the context of emerging IoT trends, like those predicted for 2025, IoT trends 2025. These trends highlight the increasing need for sophisticated algorithms to process the vast amounts of data generated by connected devices. This data-driven approach is essential for the continued advancement of machine learning.
This approach allows for automation of tasks, personalization of experiences, and the discovery of hidden patterns that might be missed by human observation. The ability to adapt to new information is crucial to the ongoing improvement of machine learning models.
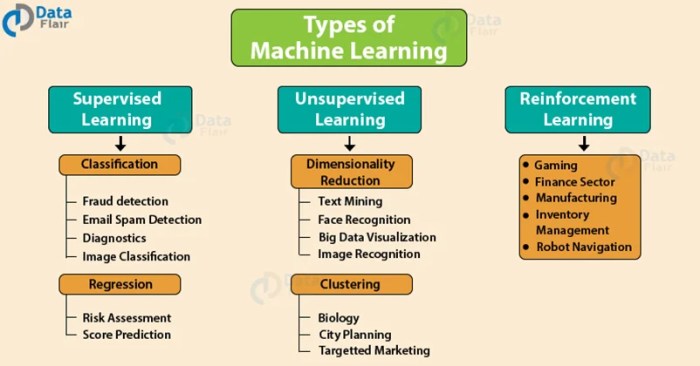
Types of Machine Learning
Machine learning can be broadly categorized into three main types: supervised, unsupervised, and reinforcement learning. Each approach employs different strategies for learning from data.
- Supervised Learning: In supervised learning, algorithms are trained on labeled data, where each data point is associated with a known output or target variable. The algorithm learns to map inputs to outputs by identifying relationships between features and the target. This is analogous to learning from examples with correct answers. Examples include spam detection, image classification, and medical diagnosis.
- Unsupervised Learning: Unsupervised learning involves algorithms that are trained on unlabeled data. The goal is to discover hidden patterns, structures, or relationships within the data without any predefined output. This approach is valuable for tasks such as customer segmentation, anomaly detection, and dimensionality reduction.
- Reinforcement Learning: Reinforcement learning is a type of machine learning where an agent learns to make optimal decisions in an environment by interacting with it and receiving rewards or penalties. The agent learns to maximize its cumulative reward over time. This approach is often used in game playing, robotics, and control systems. For instance, a robot learning to navigate a maze would receive rewards for reaching the exit and penalties for collisions.
Real-World Applications
Machine learning has a broad range of real-world applications across diverse industries.
- Healthcare: Machine learning algorithms can analyze medical images to detect diseases, predict patient outcomes, and personalize treatment plans.
- Finance: Machine learning is used for fraud detection, risk assessment, and algorithmic trading. Financial institutions use this to identify unusual transactions and prevent financial crime.
- E-commerce: Recommender systems, personalized product recommendations, and targeted advertising are powered by machine learning algorithms. These algorithms help online retailers to provide a more tailored shopping experience.
Supervised vs. Unsupervised Learning
This table highlights the key differences between supervised and unsupervised learning.
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data | Labeled data (input-output pairs) | Unlabeled data |
| Goal | Predict output from input | Discover hidden patterns and structures |
| Examples | Spam detection, image classification | Customer segmentation, anomaly detection |
| Algorithm Types | Regression, classification | Clustering, dimensionality reduction |
Algorithms in Machine Learning
Machine learning algorithms are the core of any machine learning system. They provide the specific instructions for the system to learn from data and make predictions or decisions. Understanding these algorithms is crucial for developing effective and efficient machine learning models. Different algorithms excel in different tasks, and choosing the right one depends on the nature of the problem and the available data.
Types of Machine Learning Algorithms
Various algorithms exist, each with its own strengths and weaknesses. These algorithms can be broadly categorized into several types, such as supervised, unsupervised, and reinforcement learning. This section will focus on common supervised learning algorithms.
Linear Regression
Linear regression is a fundamental supervised learning algorithm used for predicting a continuous target variable. It establishes a linear relationship between the input features and the target variable. The algorithm aims to find the best-fitting line (or hyperplane in multiple dimensions) that minimizes the error between the predicted and actual values. A simple example of linear regression is predicting house prices based on size and location.
The equation for a simple linear regression model is typically represented as: y = mx + b, where ‘y’ is the predicted value, ‘x’ is the input feature, ‘m’ is the slope, and ‘b’ is the y-intercept.
Decision Trees, Machine Learning
Decision trees are supervised learning algorithms that create a tree-like model of decisions and their possible consequences. They recursively partition the data based on the values of input features, creating branches that lead to a prediction. A practical example is classifying emails as spam or not spam based on characteristics like sender, subject, and content. The structure of a decision tree is hierarchical and resembles a flowchart, where each internal node represents a test on an attribute, each branch represents an outcome of the test, and each leaf node holds a class label.
Support Vector Machines (SVMs)
Support vector machines are supervised learning algorithms used for classification and regression tasks. They work by finding the optimal hyperplane that maximizes the margin between different classes in the data. SVMs are particularly effective in high-dimensional spaces and are often used for complex classification problems. For example, SVMs are often used in image recognition, where they can classify images into different categories based on their features.
The mathematical foundation of SVMs involves finding the maximum-margin hyperplane that separates the data points.
Comparison of Algorithms
| Algorithm | Strengths | Weaknesses | Common Use Cases |
|---|---|---|---|
| Linear Regression | Simple to understand and implement; computationally efficient | Assumes a linear relationship between variables; sensitive to outliers | Predicting house prices, sales forecasting, stock market prediction |
| Decision Trees | Easy to interpret and visualize; handles both numerical and categorical data | Prone to overfitting; can be unstable with small changes in the data | Medical diagnosis, customer churn prediction, fraud detection |
| Support Vector Machines | Effective in high-dimensional spaces; can handle complex non-linear relationships | Computational cost can be high for large datasets; parameter tuning can be challenging | Image classification, text categorization, bioinformatics |
Data Preprocessing in Machine Learning
Data preprocessing is a crucial step in the machine learning pipeline. Raw data often contains inconsistencies, errors, and irrelevant information that can negatively impact the performance of machine learning models. Effective preprocessing techniques are essential for improving model accuracy, robustness, and efficiency. Properly prepared data leads to more reliable and insightful results from the learning process.Data preprocessing involves transforming raw data into a format suitable for machine learning algorithms.
This includes tasks like cleaning, transforming, and scaling the data to ensure it is consistent, accurate, and readily usable by the chosen algorithms. The quality of the preprocessed data directly impacts the performance of the resulting model.
Importance of Data Preprocessing
Data preprocessing is paramount because raw data is often incomplete, inconsistent, and noisy. This can lead to inaccurate model predictions and unreliable insights. By addressing these issues during preprocessing, we improve the quality and reliability of the data used to train the model. The result is more accurate and robust machine learning models.
Data Cleaning
Data cleaning aims to identify and handle inconsistencies, errors, and missing values in the dataset. This process is vital for building reliable machine learning models. Cleaning ensures the data’s integrity and consistency, preventing errors from propagating through the model. Cleaning typically involves handling missing values, removing duplicates, and correcting errors in the data.
Data Transformation
Data transformation involves converting the data into a suitable format for machine learning algorithms. This can include tasks like converting categorical variables into numerical representations (one-hot encoding) or scaling numerical features. Transformation improves the performance of algorithms by addressing potential issues in the data’s representation. Effective transformations enhance the model’s ability to learn from the data.
Feature Scaling
Feature scaling normalizes the range of values for numerical features. This is essential for algorithms that are sensitive to feature scales, like support vector machines and distance-based algorithms. Feature scaling improves model performance by preventing features with larger values from dominating the learning process. Techniques such as standardization and normalization are used for feature scaling.
Handling Missing Values
Missing values are common in datasets. Several strategies can be used to handle them, including imputation with the mean, median, or mode, or removal of rows or columns containing missing values. Appropriate strategies depend on the nature of the missing data and the specific algorithm being used.
Handling Outliers
Outliers are data points that deviate significantly from the rest of the data. These points can significantly affect the model’s performance. Techniques like capping, winsorization, or removal can be employed to mitigate the impact of outliers. These methods are applied to ensure the model’s robustness and accuracy.
Python Libraries for Data Preprocessing
Python libraries like Pandas and Scikit-learn provide efficient tools for data preprocessing tasks. Pandas facilitates data manipulation, cleaning, and transformation. Scikit-learn offers various tools for feature scaling, handling missing values, and more. These libraries streamline the data preprocessing process and enhance the efficiency of model development.
Example: Handling Missing Values with Pandas
“`pythonimport pandas as pd# Sample DataFrame with missing valuesdata = ‘col1’: [1, 2, None, 4, 5], ‘col2’: [6, 7, 8, 9, 10]df = pd.DataFrame(data)# Impute missing values with the meandf[‘col1’] = df[‘col1’].fillna(df[‘col1’].mean())print(df)“`This example demonstrates how Pandas can be used to fill missing values in a DataFrame. The `fillna()` method imputes the missing value with the mean of the ‘col1’ column.
Example: Feature Scaling with Scikit-learn
“`pythonfrom sklearn.preprocessing import StandardScalerimport numpy as np# Sample datadata = np.array([[1, 2], [2, 4], [3, 8], [4, 16], [5, 32]])# Create a StandardScaler objectscaler = StandardScaler()# Fit and transform the datascaled_data = scaler.fit_transform(data)print(scaled_data)“`This example showcases how Scikit-learn can be used to standardize numerical features. The `StandardScaler` transforms the data to have zero mean and unit variance.
Model Evaluation and Selection
Evaluating and selecting the best-performing machine learning model is crucial for deploying effective solutions. This process involves assessing different models’ performance against a set of predefined criteria and choosing the one that most accurately reflects the desired outcomes. A robust evaluation strategy is vital for avoiding overfitting, ensuring generalizability, and ultimately achieving optimal results.
Methods for Evaluating Model Performance
Various methods are employed to evaluate the performance of machine learning models. These methods often involve dividing the available data into training, validation, and testing sets. The training set is used to train the model, the validation set is used to tune the model’s parameters, and the testing set is used to assess the model’s performance on unseen data.
Cross-validation techniques are also commonly used to provide a more robust estimate of a model’s generalization ability. These methods help prevent overfitting, a common pitfall in machine learning where a model performs exceptionally well on the training data but poorly on new, unseen data.
Metrics for Assessing Model Accuracy
Several metrics are employed to quantify the accuracy of a machine learning model. These metrics provide valuable insights into the model’s performance, guiding the selection of the optimal model for a specific task.
- Precision: Precision measures the proportion of correctly predicted positive instances out of all predicted positive instances. A high precision indicates that the model is less likely to misclassify negative instances as positive instances. For example, in a spam detection system, high precision ensures that fewer legitimate emails are incorrectly flagged as spam.
- Recall: Recall measures the proportion of correctly predicted positive instances out of all actual positive instances. A high recall indicates that the model is less likely to miss positive instances. In medical diagnosis, high recall is crucial to ensure that patients with a disease are correctly identified.
- F1-score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of both aspects of model performance, especially useful when precision and recall are equally important. The F1-score is often used in situations where minimizing both false positives and false negatives is desired.
- Accuracy: Accuracy measures the overall correctness of the model’s predictions. It represents the proportion of correctly classified instances out of the total instances. While seemingly straightforward, accuracy can be misleading if the dataset has an imbalanced class distribution. For instance, if a dataset contains 90% of one class and 10% of another, a model that always predicts the majority class would achieve high accuracy, but this model would be useless for accurately predicting the minority class.
- AUC (Area Under the ROC Curve): The AUC provides a measure of the model’s ability to distinguish between classes. It’s particularly useful when dealing with binary classification problems. AUC values closer to 1 indicate better performance in separating the classes.
Model Selection Process
Selecting the best-performing model involves a systematic approach. This process involves comparing the performance metrics of different models, considering factors like computational cost, interpretability, and model complexity.
- Comparative Analysis: Evaluate different models using the same dataset and metrics. This allows for a fair comparison of their performance.
- Parameter Tuning: Optimize the parameters of each model to achieve the best possible performance. This may involve techniques such as grid search or random search to find the optimal parameter combination.
- Feature Engineering: Examine and potentially enhance the features used to train the model. Feature engineering may be a crucial step to improve model performance.
- Cross-validation: Employing cross-validation techniques provides a robust estimate of the model’s generalization ability, offering insights into how the model will perform on unseen data.
Comparison of Evaluation Metrics
| Metric | Description | Implications |
|---|---|---|
| Precision | Proportion of correctly predicted positives out of predicted positives. | High precision means fewer false positives. |
| Recall | Proportion of correctly predicted positives out of actual positives. | High recall means fewer false negatives. |
| F1-score | Harmonic mean of precision and recall. | Balances precision and recall, useful when both are important. |
| Accuracy | Overall correctness of predictions. | Can be misleading with imbalanced datasets. |
| AUC | Area under the ROC curve. | Measures the model’s ability to distinguish between classes. |
Machine Learning in Different Domains
Machine learning’s impact transcends specific sectors, permeating various aspects of modern life. Its adaptability and problem-solving capabilities have revolutionized how we approach tasks in healthcare, finance, and marketing, automating processes, improving accuracy, and fostering efficiency. This section explores the diverse applications of machine learning in these key domains, highlighting the challenges and opportunities unique to each.The practical applications of machine learning are rapidly expanding, showcasing its potential across industries.
From analyzing medical images to predicting market trends, machine learning algorithms are driving innovation and offering new avenues for problem-solving. By understanding the specific applications and challenges within different domains, we can better appreciate the broad scope and transformative power of machine learning.
Machine Learning in Healthcare
Machine learning algorithms are revolutionizing healthcare diagnostics, treatment, and drug discovery. Their ability to analyze vast datasets of medical images, patient records, and genomic data is proving invaluable in identifying patterns and predicting outcomes.
- Disease Prediction and Risk Assessment: Machine learning models can analyze patient data to predict the likelihood of developing certain diseases, enabling proactive interventions and personalized preventative measures. For example, algorithms can assess factors like lifestyle, family history, and genetic predispositions to predict the risk of heart disease or diabetes, allowing for early intervention and improved patient outcomes.
- Drug Discovery and Development: Machine learning accelerates the process of identifying potential drug candidates and optimizing their efficacy. By analyzing vast datasets of chemical compounds and biological interactions, algorithms can predict which compounds are most likely to be effective against specific diseases, reducing the time and resources needed for drug development.
- Medical Image Analysis: Machine learning algorithms can analyze medical images such as X-rays, CT scans, and MRIs to detect anomalies and assist in diagnoses. These algorithms can quickly and accurately identify cancerous tumors, fractures, and other abnormalities, improving the speed and accuracy of medical diagnoses.
The challenges in healthcare applications include data privacy and security concerns, the need for high-quality and reliable data, and ensuring the ethical use of machine learning algorithms. The opportunities are immense, offering the potential to personalize medicine, improve patient outcomes, and reduce healthcare costs.
Machine Learning in Finance
Machine learning is transforming the financial sector, automating tasks, detecting fraud, and improving investment strategies. Its ability to analyze large datasets of financial transactions and market data allows for more accurate predictions and informed decisions.
- Fraud Detection: Machine learning algorithms can identify patterns and anomalies in financial transactions that may indicate fraudulent activity. These algorithms can detect unusual spending patterns, suspicious account activity, and other indicators of fraud, reducing financial losses and improving security.
- Risk Management: Machine learning models can analyze various factors to assess credit risk and predict potential loan defaults. By analyzing credit history, income, and other relevant factors, algorithms can predict the likelihood of loan repayment, enabling better risk management and reducing losses.
- Algorithmic Trading: Machine learning algorithms can analyze market data and identify trading opportunities in real-time. These algorithms can analyze vast datasets of market trends, news events, and economic indicators to make informed investment decisions, potentially leading to increased profits.
Data security and regulatory compliance are crucial considerations in financial applications of machine learning. Ensuring the accuracy and reliability of the data is essential for avoiding biases and ensuring responsible decision-making.
Machine Learning in Marketing
Machine learning is increasingly used in marketing to personalize customer experiences, optimize campaigns, and improve customer engagement. Its ability to analyze vast datasets of customer data enables targeted advertising, improved customer segmentation, and enhanced marketing strategies.
- Customer Segmentation and Targeting: Machine learning algorithms can analyze customer data to identify patterns and segment customers based on their needs and preferences. This allows marketers to tailor their messages and offerings to specific customer groups, increasing engagement and conversion rates.
- Personalized Recommendations: Machine learning models can analyze customer browsing history, purchase patterns, and other data to provide personalized product recommendations. This enhances customer experience and increases sales.
- Predictive Analytics for Campaign Optimization: Machine learning algorithms can analyze past campaign data to predict the effectiveness of future campaigns and optimize marketing strategies. This helps in allocating resources efficiently and maximizing campaign ROI.
Data privacy and ethical considerations are vital in marketing applications of machine learning. Maintaining data security and ensuring transparency in how customer data is used are crucial for building trust and avoiding misuse.
Ethical Considerations in Machine Learning
Machine learning models, while powerful tools, can perpetuate and amplify existing societal biases. Their use necessitates careful consideration of ethical implications, ensuring fairness, transparency, and accountability. Ignoring these factors can lead to discriminatory outcomes and erode public trust.Machine learning algorithms are trained on data, and if this data reflects existing societal biases, the model will likely replicate and potentially exacerbate those biases.
This raises crucial questions about the responsibility of developers and users to mitigate these biases and ensure equitable outcomes.
Potential Ethical Concerns
Addressing the ethical implications of machine learning systems is paramount. Bias in algorithms can manifest in various ways, leading to unfair or discriminatory outcomes. For example, a loan application model trained on historical data that reflects existing racial or gender disparities might deny loans to individuals from underrepresented groups, perpetuating existing inequalities. Furthermore, the lack of transparency in some models can make it difficult to understand why a specific decision was made, hindering accountability and potentially leading to accusations of unfair treatment.
The potential for misuse, like profiling or surveillance, is another critical concern. Algorithmic decision-making, if not carefully considered, could disproportionately impact certain demographics.
Bias in Machine Learning Models
Machine learning models are trained on data, and if this data reflects existing societal biases, the model will likely replicate and potentially exacerbate those biases. This can manifest in various forms, including racial, gender, or socioeconomic bias. For example, a hiring algorithm trained on data from a company with a history of excluding certain demographic groups may perpetuate that bias.
This leads to a cascade of negative consequences, creating and reinforcing discriminatory outcomes.
Mitigation Strategies for Bias
Mitigating bias in machine learning models requires a multifaceted approach. One crucial step is ensuring the data used for training is representative of the population the model will serve. Additionally, carefully evaluating the model’s output for potential biases is essential. Techniques such as fairness-aware algorithms and adversarial debiasing methods can help identify and mitigate bias. Finally, transparent documentation and clear communication of model limitations and potential biases are vital to responsible deployment.
Responsible Use of Machine Learning in Society
The responsible use of machine learning necessitates a commitment to fairness, transparency, and accountability. Developers and users must consider the potential impact of their models on various demographics and strive to create systems that are equitable and beneficial for all. Continuous monitoring and evaluation of models are critical to identify and address emerging biases or unintended consequences. Furthermore, mechanisms for redress and appeals should be in place for individuals negatively impacted by machine learning decisions.
Ensuring Fairness and Transparency in Machine Learning Systems
Fairness and transparency are crucial for building trust in machine learning systems. To ensure fairness, the development process should include careful consideration of the potential impact on different demographic groups. The data used for training should be diverse and representative, and the model should be evaluated for potential biases. Transparency in machine learning systems can be achieved through explainable AI (XAI) techniques.
These methods aim to provide insights into how a model arrives at its decisions, increasing understanding and accountability. This understanding is crucial for building public trust and mitigating potential harms.
Deployment and Maintenance of Machine Learning Models
Deploying machine learning models into production environments is a crucial step in realizing the value of these models. This involves translating the trained models into a format suitable for use in a real-world application, ensuring scalability and reliability. Maintenance encompasses continuous monitoring of performance and adapting the model to evolving data and business needs. This crucial stage is often overlooked but is essential for sustained model effectiveness.
Model Deployment Process
The deployment process typically involves several steps. First, the model is packaged into a deployable format, often an executable or a web service. Next, this package is integrated into the existing application infrastructure. This integration may involve API calls, custom integrations with existing systems, or other methods, depending on the application’s architecture. Finally, the model is made available for use, allowing the application to interact with the model and receive predictions or classifications.
This involves considerations for scalability, ensuring the system can handle the expected volume of requests, and for security, protecting the model and the data it uses.
Challenges in Model Maintenance
Maintaining machine learning models in production presents several significant challenges. Data drift, where the distribution of input data changes over time, is a major concern. This shift can lead to a decline in model performance, as the model is no longer accurate in predicting outcomes for the new data. Another key challenge is model obsolescence, where the model’s accuracy degrades over time due to the arrival of new information not accounted for during training.
This can necessitate retraining or updating the model with new data. Model interpretability, especially in complex models, can also pose a challenge. Understanding how the model arrives at its predictions is crucial for trust and for debugging issues. Finally, the need for continuous monitoring and evaluation is a significant part of ongoing maintenance.
Monitoring Model Performance
Monitoring model performance in production is crucial for ensuring continued accuracy and identifying potential issues early. Key performance indicators (KPIs) such as accuracy, precision, recall, and F1-score are routinely tracked. These metrics provide a quantitative measure of the model’s performance on new data. Real-time monitoring tools can be employed to track these metrics and alert administrators to performance degradation.
For example, a sudden drop in accuracy might signal the need for retraining or a change in the input data. A dashboard showing these metrics over time can provide valuable insights into model behavior. Visualizing these metrics over time can provide a clear picture of the model’s performance, aiding in proactive identification of issues.
Retraining Models with New Data
Retraining models with new data is essential to maintain model accuracy and adapt to changing conditions. This process involves gathering new data, preparing it for use, and then retraining the model using the updated dataset. A key consideration is determining how often to retrain. This frequency depends on the rate of change in the data, the model’s complexity, and the cost of retraining.
For instance, a model predicting customer churn might need to be retrained monthly to reflect changing customer behavior, while a model predicting stock prices might require retraining daily. The process of retraining should be automated to minimize downtime and maximize efficiency. Strategies for automated retraining, including scheduling and version control, are essential for continuous model improvement.
Future Trends in Machine Learning
Machine learning is rapidly evolving, driven by advancements in computing power, data availability, and algorithmic sophistication. This evolution promises to reshape numerous industries and create novel applications. The future holds exciting possibilities, yet also potential challenges that need careful consideration.
Emerging Trends and Advancements
Several significant trends are shaping the future of machine learning. These include the increasing use of deep learning architectures, the rise of explainable AI (XAI), the growing importance of federated learning, and the integration of machine learning with edge computing. These trends promise to enhance the capabilities and efficiency of machine learning systems.
Impact on Various Industries
Machine learning’s influence extends across numerous sectors. In healthcare, it can lead to earlier disease diagnosis and personalized treatment plans. In finance, it facilitates fraud detection and risk assessment. Furthermore, in manufacturing, it drives process optimization and predictive maintenance. The potential impact on each sector is substantial and diverse.
Innovative Applications in the Future
Machine learning will empower novel applications in diverse fields. Personalized education platforms tailored to individual learning styles are one example. Furthermore, advanced image recognition systems can be utilized for improved environmental monitoring. These applications highlight the wide-ranging impact of machine learning.
Potential Benefits
The potential benefits of these future trends are substantial. Improved healthcare outcomes, increased efficiency in industries, and enhanced decision-making are some examples. These benefits stem from the ability of machine learning to analyze vast amounts of data and extract valuable insights.
Machine learning is rapidly evolving, pushing the boundaries of what’s possible in various fields. Recent breakthroughs in the field, like those highlighted in Breakthrough inventions , are dramatically impacting how we approach problem-solving. From self-driving cars to personalized medicine, these advancements are reshaping the future, and machine learning is at the heart of it all.
Potential Risks
Despite the benefits, potential risks associated with these trends exist. Bias in training data can lead to unfair or discriminatory outcomes. The deployment of autonomous systems requires careful consideration of safety and accountability. Furthermore, the potential job displacement from automation is a crucial concern.
Explainable AI (XAI)
Explainable AI focuses on developing machine learning models whose decisions are understandable and interpretable. This addresses the “black box” problem inherent in some complex models, allowing stakeholders to trust and understand the reasoning behind predictions. Understanding the decision-making process is essential for building trust and mitigating potential biases.
Federated Learning
Federated learning allows training machine learning models on decentralized datasets without transferring the data to a central location. This addresses privacy concerns and enables training on data held by multiple organizations or individuals. The growing need for privacy-preserving techniques is crucial for data security.
Edge Computing Integration
Machine learning models are increasingly deployed on edge devices, processing data locally instead of transmitting it to a central server. This approach enhances speed, efficiency, and privacy, particularly relevant in applications such as real-time object detection or predictive maintenance. Edge computing is critical for low-latency applications.
Deep Learning Architectures
Deep learning architectures, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs), are becoming increasingly sophisticated and powerful. These architectures are capable of handling complex data types and extracting intricate patterns, which is essential for tasks like image recognition, natural language processing, and speech recognition.
Table of Examples
| Industry | Application | Impact |
|---|---|---|
| Healthcare | Personalized treatment plans | Improved patient outcomes |
| Finance | Fraud detection | Reduced financial losses |
| Manufacturing | Predictive maintenance | Increased efficiency and reduced downtime |
Tools and Libraries for Machine Learning
Machine learning thrives on readily available tools and libraries, simplifying model development and deployment. These resources empower practitioners to tackle complex problems efficiently, fostering innovation and progress in the field. The right selection of tools is crucial for achieving optimal results and handling specific tasks effectively.Effective machine learning hinges on choosing the right tools. Libraries like TensorFlow and PyTorch offer robust frameworks for deep learning, while Scikit-learn provides a comprehensive suite of algorithms for various machine learning tasks.
Each tool possesses unique strengths, making them suitable for particular applications. Understanding these distinctions is vital for selecting the most appropriate library for a given project.
Popular Machine Learning Tools and Libraries
Various libraries provide the building blocks for machine learning tasks. TensorFlow and PyTorch are renowned for deep learning, while Scikit-learn excels in traditional machine learning. Each library offers distinct functionalities, making them suitable for diverse applications.
- TensorFlow: A comprehensive open-source library developed by Google, TensorFlow is a popular choice for building and training deep learning models. Its flexibility allows for the creation of intricate neural networks, handling complex data structures. TensorFlow’s graph-based approach facilitates efficient computation and allows for parallel processing. It’s widely adopted for tasks such as image recognition, natural language processing, and speech recognition.
- PyTorch: Developed by Facebook’s AI Research team, PyTorch is another prominent deep learning framework. Its dynamic computational graph allows for greater flexibility and ease of debugging compared to TensorFlow. PyTorch’s intuitive syntax and strong community support make it a favorite among researchers and practitioners. It’s often preferred for tasks involving rapid prototyping and experimentation.
- Scikit-learn: A powerful library for various machine learning tasks, Scikit-learn provides a wide range of algorithms, including classification, regression, clustering, and dimensionality reduction. It simplifies the process of model building, training, and evaluation. Scikit-learn’s ease of use and extensive documentation make it a valuable tool for beginners and experienced practitioners alike. It is a go-to library for tasks like predicting customer churn or identifying fraudulent transactions.
Functionalities and Capabilities
These libraries offer diverse functionalities crucial for machine learning tasks. TensorFlow and PyTorch excel in deep learning, while Scikit-learn caters to traditional machine learning algorithms.
- TensorFlow: TensorFlow excels at constructing and training complex neural networks. Its tensor-based operations allow for efficient handling of multi-dimensional data. It features tools for deploying models in various environments, ensuring seamless integration.
- PyTorch: PyTorch’s dynamic computation graph simplifies debugging and experimentation. Its intuitive syntax promotes rapid prototyping and facilitates experimentation with different model architectures. PyTorch’s automatic differentiation capabilities enable efficient gradient calculation, crucial for training deep learning models.
- Scikit-learn: Scikit-learn provides a collection of readily available machine learning algorithms, including support vector machines, decision trees, and random forests. It offers tools for data preprocessing, model selection, and evaluation. Scikit-learn’s ease of use and comprehensive documentation make it an excellent choice for tasks requiring rapid model development.
Example Usage
These libraries enable building and training machine learning models efficiently. Here are simplified examples demonstrating their use.
- Scikit-learn: “`python
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split# … (Load and preprocess data) …
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(f”Accuracy: accuracy”)
“`
Comparison Table
This table summarizes the strengths and weaknesses of different machine learning libraries.
| Library | Strengths | Weaknesses |
|---|---|---|
| TensorFlow | Powerful deep learning capabilities, extensive ecosystem, production-ready deployment tools | Steeper learning curve compared to Scikit-learn, can be more complex to use for basic tasks |
| PyTorch | Flexible dynamic computation graph, intuitive syntax, strong research community | May not be as mature for production deployment as TensorFlow, less extensive pre-built models |
| Scikit-learn | Ease of use, wide range of traditional machine learning algorithms, comprehensive documentation | Limited deep learning capabilities, may not be optimal for extremely complex models |
Final Summary
In conclusion, Machine Learning offers a powerful toolkit for tackling complex problems across diverse domains. From understanding the nuances of different algorithms to navigating the ethical implications, this guide provides a comprehensive overview. The future of machine learning promises exciting advancements, and by understanding the core principles, ethical considerations, and practical applications, we can harness its potential for positive impact in the world.
FAQ Summary
What are the different types of Machine Learning?
Machine learning encompasses supervised, unsupervised, and reinforcement learning. Supervised learning involves training models on labeled data, unsupervised learning on unlabeled data, and reinforcement learning involves training agents to make decisions in an environment to maximize rewards.
What is the importance of data preprocessing in machine learning?
Data preprocessing is crucial for building effective machine learning models. It involves cleaning, transforming, and preparing data for modeling, ensuring data quality and consistency, thereby improving model accuracy and reliability.
What are some common challenges in deploying machine learning models?
Deploying machine learning models can present challenges such as ensuring model performance consistency, maintaining and updating models over time, and monitoring their performance in real-world scenarios.
How can bias be mitigated in machine learning models?
Bias in machine learning models can stem from biased training data. Mitigating bias requires careful data selection, model evaluation, and ongoing monitoring to ensure fairness and transparency.





